Learning-AI
🦩 Flamingo: a Visual Language Model for Few-Shot Learning
June 2023
tl;dr: A visually-conditioned autoregressive text generation models. It takes in interleaved text token and images/videos, and produce texts as output.
Overall impression
Flamingo teaches LLM how to “see”. A frozen vision encoder and frozen LLM decoder is used, only with adaptor layers learned. It augments pretrained language models with a mechanism to directly attend to a single context image. The visual-condition is done via the adaptor mechanism. Flamingo promotes modular design of AGI.
Strong performance with few-shot prompts can be done for image and video understanding tasks such as classification, captioning, or question-answering: these can be cast as text prediction problems with visual input conditioning. Note that these vision language tasks have language as the natural form of output. For vision-centric tasks such as object detection, see models such as pix2seq, pix2seq v2 and VisionLLM.
The challenge is to inject a multimodal prompt containing images, interleaved with text.
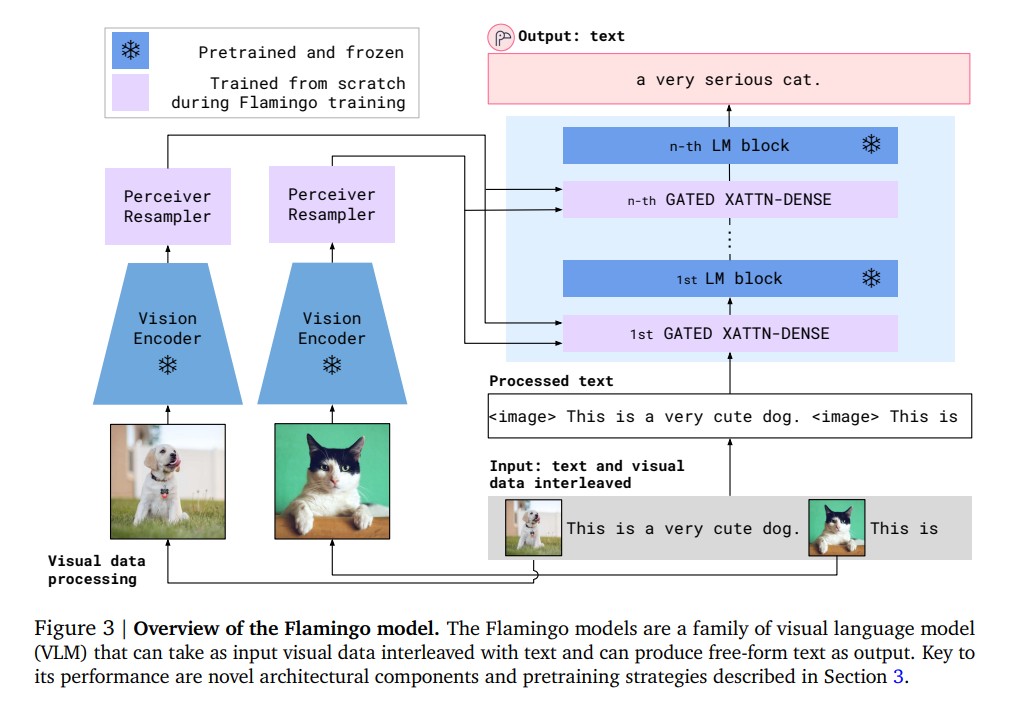
Key ideas
- Vision backbone and LLM decoder is frozen.
- Add perceiver sampler to keep the vision feature tokens the same number and benefit from the larger image size in a scalable way.
- Insert gated cross-attention dense blocks between the original and frozen llm block layers, trained from scratch. Tanh was used which generates the same results at initialization.
Technical details
- The model can take in high resolution images and videos, as it uses perceiver structure that can produce a small number of visual token per image/video.
Notes
- Questions and notes on how to improve/revise the current work