Learning-AI
CaDDN: Categorical Depth Distribution Network for Monocular 3D Object Detection
March 2021
tl;dr: Lift perspective image to BEV for mono3D, with direct depth supervison. It can be seen as an extension to Pseudo-lidar.
Overall impression
CaDDN focuses on accurate prediction of depth to improve mono3D performance. The depth prediction method is based on improved version of ordinal regression.
The idea of projecting perspective image to BEV representation and then perform object detection is quite similar to that of OFT and Lift Splat Shoot. These implicit method transforms feature map to BEV space and suffers from feature smearing. CaDDN leverages probabilistic depth estimation via categorical depth distribution.
Previous depth prediction is separated from 3D detection during training, preventing depth map estimates from being optimized for detection task. In other words, not all pixels are created equal. Accurate depth should be prioritized for pixels belonging to objects of interest, and is less important of background pixels. CaDDN focuses on generating an interpretable depth representation for mono3D. –> cf ForeSeE
Key ideas
- Depth distribution supervision
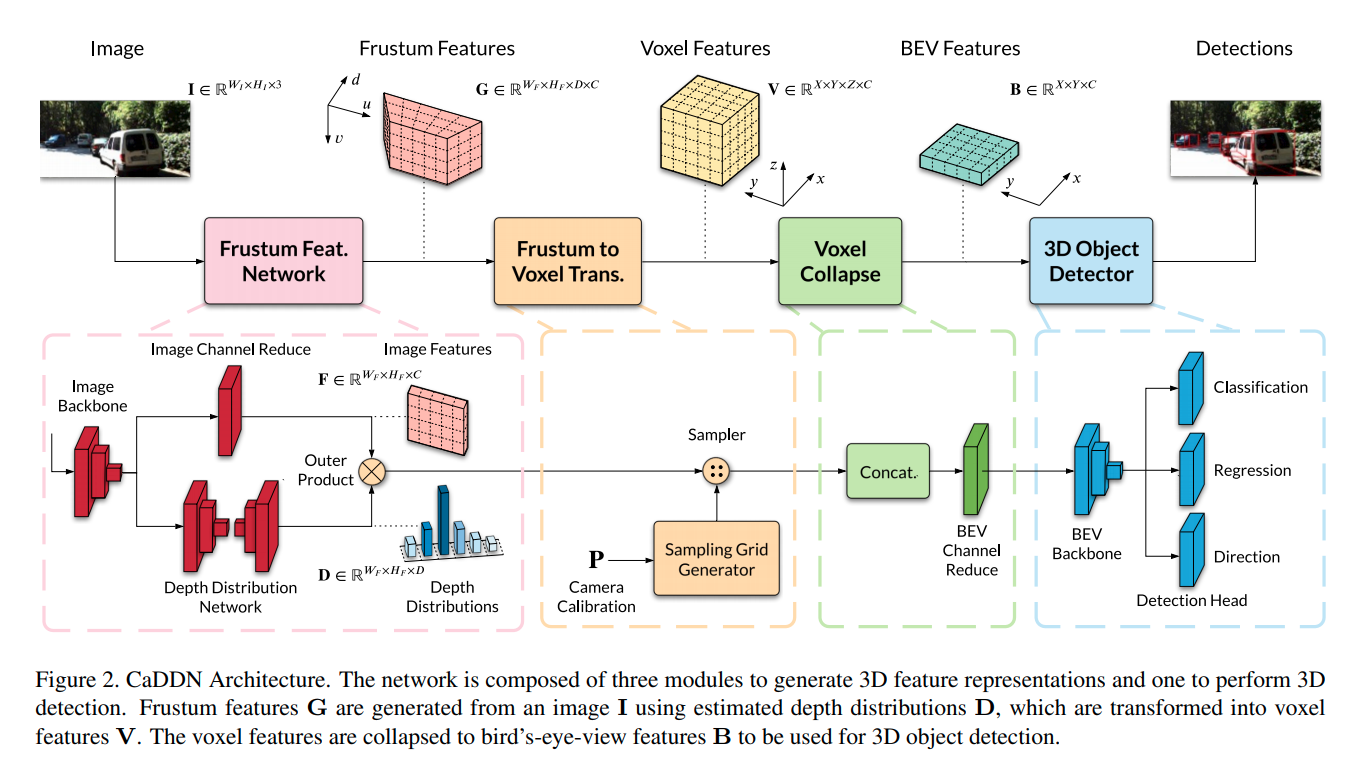
- Architecture
- Input image $W_I \times H_I \times 3$
- Frustum feature grid
- Voxel grid
- BEV feature grid
- Frustum feature network
- D: Depth distribution network, with direct depth supervision
- Input: image feature from block1 of resnet, $W_F \times H_F \times C(=256)$
- Output: image feature from block1 of resnet, D with size $W_F \times H_F \times D$
- F: Channel reduction of image feature, with size $W_F \times H_F \times C(=64)$
- Outer product $G=D \otimes F$
- Output: Frustum feature grid: G with size $W_F \times H_F \times D \times C$
- Outer product: feature pixels are weighted by depth probability using outer product. This step encapsulates the C channel features in each of the 3D voxel bins (although the 3D voxels bins are still in the form of image + depth bins).
- D: Depth distribution network, with direct depth supervision
- Frustum to voxel conversion
- Trilinear interpolation with known camera intrinsics
- Input G
- Output V with size $X \times Y \times Z \times C$
- Voxel collapse to BEV
- Z*C is stacked and reduced to C with 1x1 convolution.
Technical details
- Voxel size = 0.16 m for mono3D.
- The authors did not do nuScenes as 32 line lidar is too sparse for depth completion.
- How to understand the channels C of frustum feature G and volume feature V? It is like the 3 channels for RGB image. For features, we increased the channels, but the C channel vector is still associated with a 3D location.