Learning-AI
DTP: Dynamic Task Prioritization for Multitask Learning
August 2019
tl;dr: Dynamically adjust the weight of tasks during training based on training progress with focal loss.
Overall impression
GradNorm and dynamic task prioritization are very similar. However the weight rate adjustment is exponential as compared to focal loss (essentially also exponential), and the progress signal is loss drop as compared to KPI.
This paper is one important task in self-paced learning (automated approach to curriculum learning). Task weights are usually done with extensive grid search, and maintain static throughout time.
Contrary to curriculum learning, the paper proposes that it is important to prioritize difficult task first. Perfecting simple tasks wastes valuable resources.
This work explored two methods: 1) assign dynamic weights to tasks. 2) structure the network structure to reflect task hierarchy.
| Methods | Learning Progress Signal | hyperparameters |
|---|---|---|
| Uncertainty Weighting | Homoscedastic Uncertainty | No hyperparameters |
| GradNorm | Training loss ratio | 1 exponential weighting factor |
| Dynamic Task Prioritization | KPI | 1 focal loss scaling factor |
Key ideas
- A critical assumption of curriculum learning is that the underlying distribution across all tasks is the same but the entropy increases over time. –> this is generally not true unless manually curate such tasks.
- The idea of task prioritization is similar to example based prioritization such as hard negative mining.
- Hard parameter sharing: a single backbone feed into multiple tasks. This creates a critical layer: a layer responsible for learning representation that must satisfy all downstream objectives.
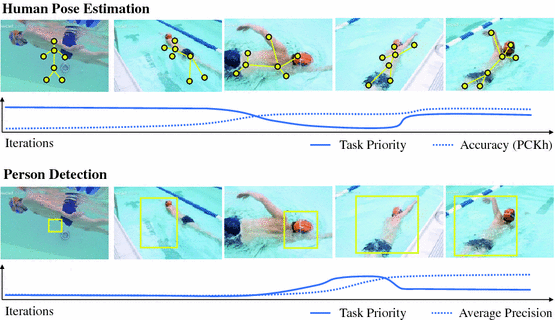
- The progress signal is chosen to be KPI $\kappa \in [0, 1]$ for the task. Difficulty $D \propto \kappa^{-1}$. KPI is smoothed via EMA.
- Focus parameters: $\gamma_0$ is example based focusing parameter, and $\gamma_1$ though $\gamma_t$ is the task level focusing parameter
- Example level prioritization is done via original focal loss $FL(p_c, \gamma_0)$ where $p_c$ is the prediction for the positive example (i.e., $1-p_c$ is the difference between prediction and label).
- Task level prioritization is $FL(\bar{\kappa}, \gamma_t)$.
- The architecture of the network can also be designed to have task hierarchy. –> this is hard to automate and is of little practical value.
Technical details
- The FL weighting term’s gradient can be detached.
- COCO: small (< 32^2), medium (32^2 ~ 96^2) and large (> 96^2).
- key-point tolerance is related to the head-neck length.
- Pose estimation (keypoints) are harder than detection.
Notes
- This work still manually craft a policy to adjust the relative weights to the tasks –> Can we learn a better policy based on progress signal? Automated curriculum learning via reinforcement learning.
- Maybe we can design a ZipperNet to learn where to split the tasks head off a common backbone? Looks like a NAS project.
- This method can be extended to incorporate with percentile to be more robust to noise. Also, renormalize the weights so they add up to one.
- 知乎 Review