Learning-AI
PyrOccNet: Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks
June 2020
tl;dr: Predict BEV semantic map from single monocular image, or multiple streams of images.
Overall impression
From the authors of OFT, and this seems to be the natural extension of and next hot topic beyond monocular 3D object detection.
Traditional stack to generate BEV map:
- SfM
- ground plane estimation
- road segmentation
- lane detection
- 3D object detection
Many of these tasks can benefit each other. Thus an end-to-end network to predict BEV map makes sense.
PyrOccNet ises direct supervision.
Key ideas
- View transformation: Dense transformation layer.
- Probabilistic semantic occupancy grid representation for easier fusion between cameras and frames. Essentially we need to predict multiclass binary labels for a BEV grid.
- Losses: weighted binary CE + uncertainty loss (encourages to be 0.5)
- Bayesian filtering for multicamera and temporal fusion.
- Architecture
- Dense Transform layer
- 1D conv to collapse height dim to fixed feature vectors
- 1D conv expands expands the feature vector along the depth axis.
- resample into Cartesian frame using intrinsics
- Multiscale transformer pyramid
- Each layer is responsible for transforming part of the image in BEV.
- Top down network: similar to OFT
- Dense Transform layer

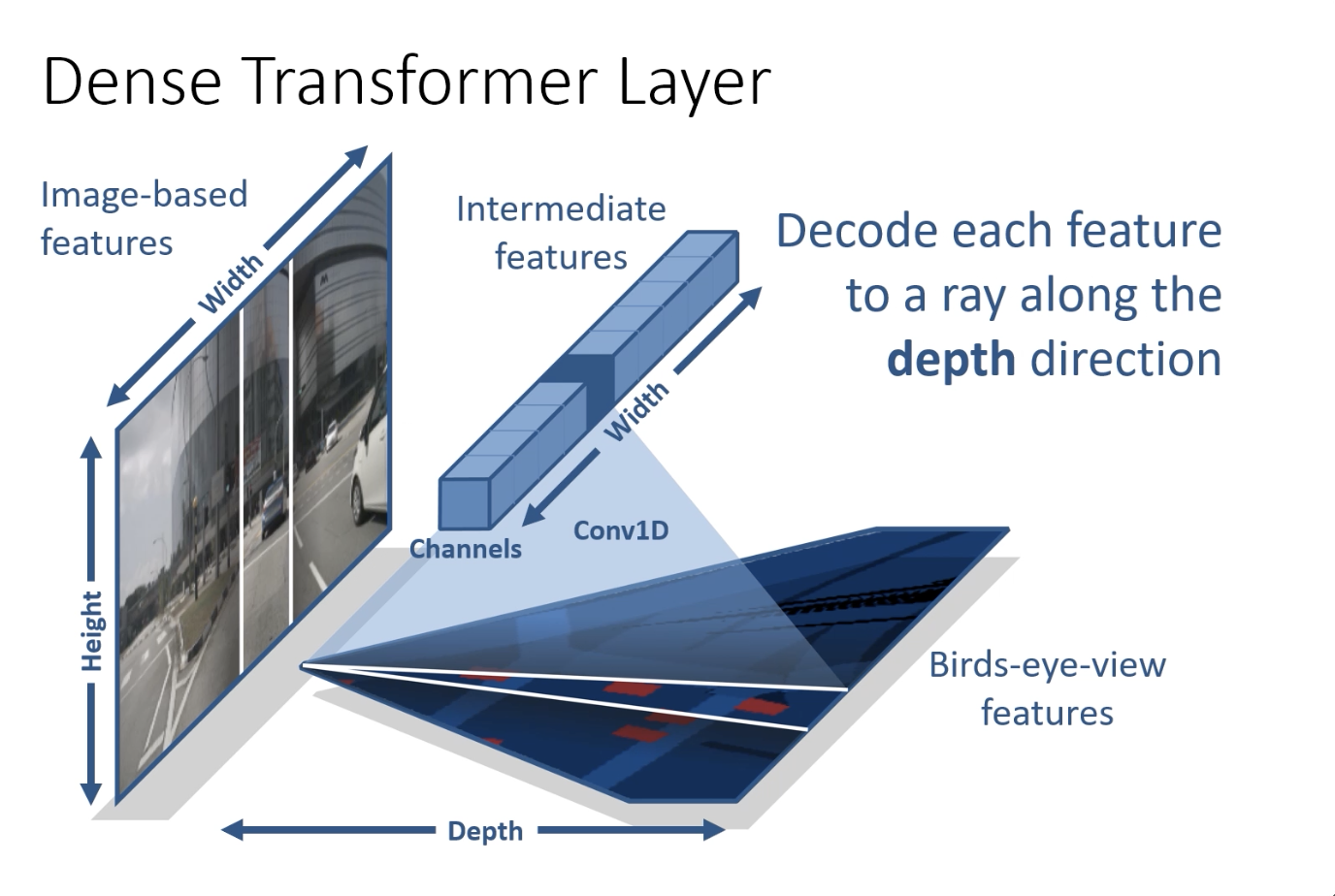
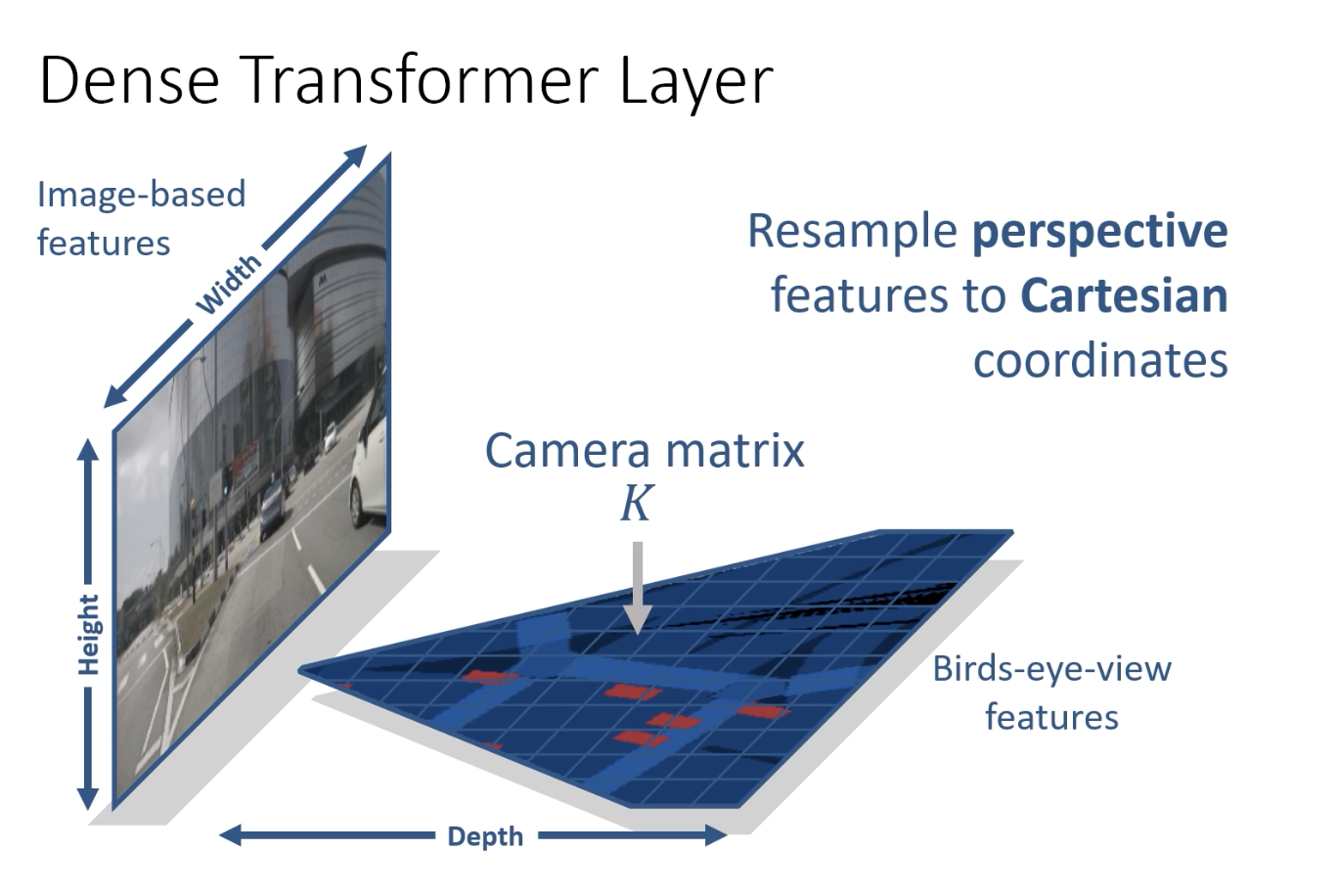
- Alternative methods
- Semantic segmentation + IPM
- Depth unprojection: semantic segmentation + depth prediction + BEV proj
- VED: view encoder-decoder
- VPN: view parsing network
- Ablation study baseline: backbone, inverse perspective mapping, sigmoid prediction: this is already quite a good baseline.
Technical details
- Binary mask to mask out grid cell outside FoV and those grid cells without lidar points.
- Weighted BCE: ~1/sqrt(N). Using ~1/N leads to overfitting to minority classes. This is further investigated in Class balanced loss based on efficient number.
- 50 x 50 m, 200 x 200 image.