Learning-AI
RetNet: Retentive Network: A Successor to Transformer for Large Language Models
September 2023
tl;dr: Efficient variant of Transformer to achieve training parallelism, low-cost inference while keeping good performance.
Overall impression
RetNet supports three computation paradigms: parallel, recurrent and chunkwise recurrent.
Transformers was initially proposed to overcome sequential training issue of recurrent models. Training parallelim of transformers comes at the cost of inefficient inference. It is the holy grail of efficient language modeling to achieve 1) training parallelism, 2) low-cost inference and 3) strong performance at the same time. This holy grail is also referred to as “the impossible triangle”.
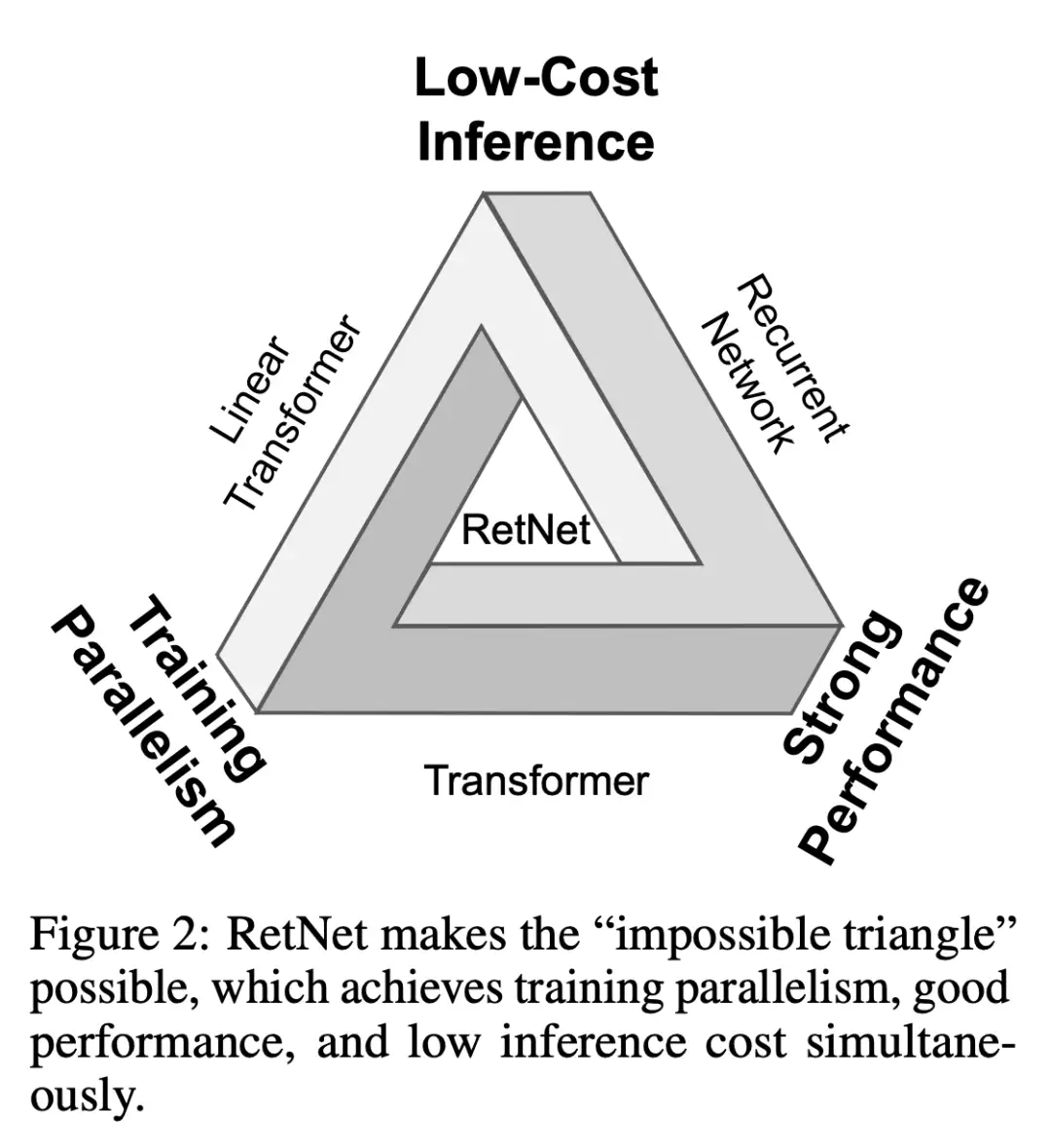
Linear attention (such as Fast Transformers) approximates attention scores exp(q, k) with kernels $\phi(q)$ and $\phi(k)$ so autoregressive inference can be rerwwritten in a recurrent form. Yet the model capability and performance are worse than Transformers, hindering their popularity. –> How is RetNet better than linear attention?
RetNet = linear attention + rope + explicit exponential decay($\gamma$)
Note that the discussion of transformers in this paper is in the context of decoder-only LLMs, so self-attention.
RWKV is very similar to RetNet.
Key ideas
- Retention
- Starting with a recurrent sequence modeling problem v_n –> o_n through hidden states s_n.
- Making very few assumptinos (diagnoalization matrix to scalar, etc), retention can be parallelized as \(Retention(X) = (QK^T \odot D)V\)
-
$D \in R^{ x \times x }$ combines causal masking and exponential decay along relative distance as one matrix. - In other words, RNNs can be formulated as linear transformers. –> Recurrent caluclulations can be done in a polynomial way.
- In comparison, transformers are \(Attention(X) = \sigma(QK^T \odot D)V.\) Attetnion has an extra softmax, which does not allow efficient reordering of computation.
- Architecture = MSR + FFN
- L identical blockes, such as in transformers.
- Multiscale Retention (MSR) Module
- Heads use multiple \gamma scales to represent different decay components. Some heads capture the more ready-to-forget components and others more lasting components.
Technical details
- The implementation is greatly simplified without key-value cache trick.
- The paper clains that RWKV does not have training parallelism. –> It is not entirely ture. In practice, RWKV is quite fast and does not need parallelization of the wkv components. But it can be parallelizable.
- Linear attention vs RWKV –> RWKV seems to be a mixture of linear transformer and AFT (attention-free transformer) (see Reference on Zhihu)
- It is not trained with nvidia cards but with AMD MI200 GPUs. –> It is said that MI200 = 5 x A100. (See Reference from 2021)
- RetNet decoding latency keeps almos tht esame across diff batch sizes and input lengths.
Notes
- Questions and notes on how to improve/revise the current work